
 Alex Cheema
Alex Cheema
4 өөрчлөгдсөн 1 нэмэгдсэн , 7 устгасан
+ 1
- 1
README.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN
docs/exo-screenshot.jpg
{kind=link}
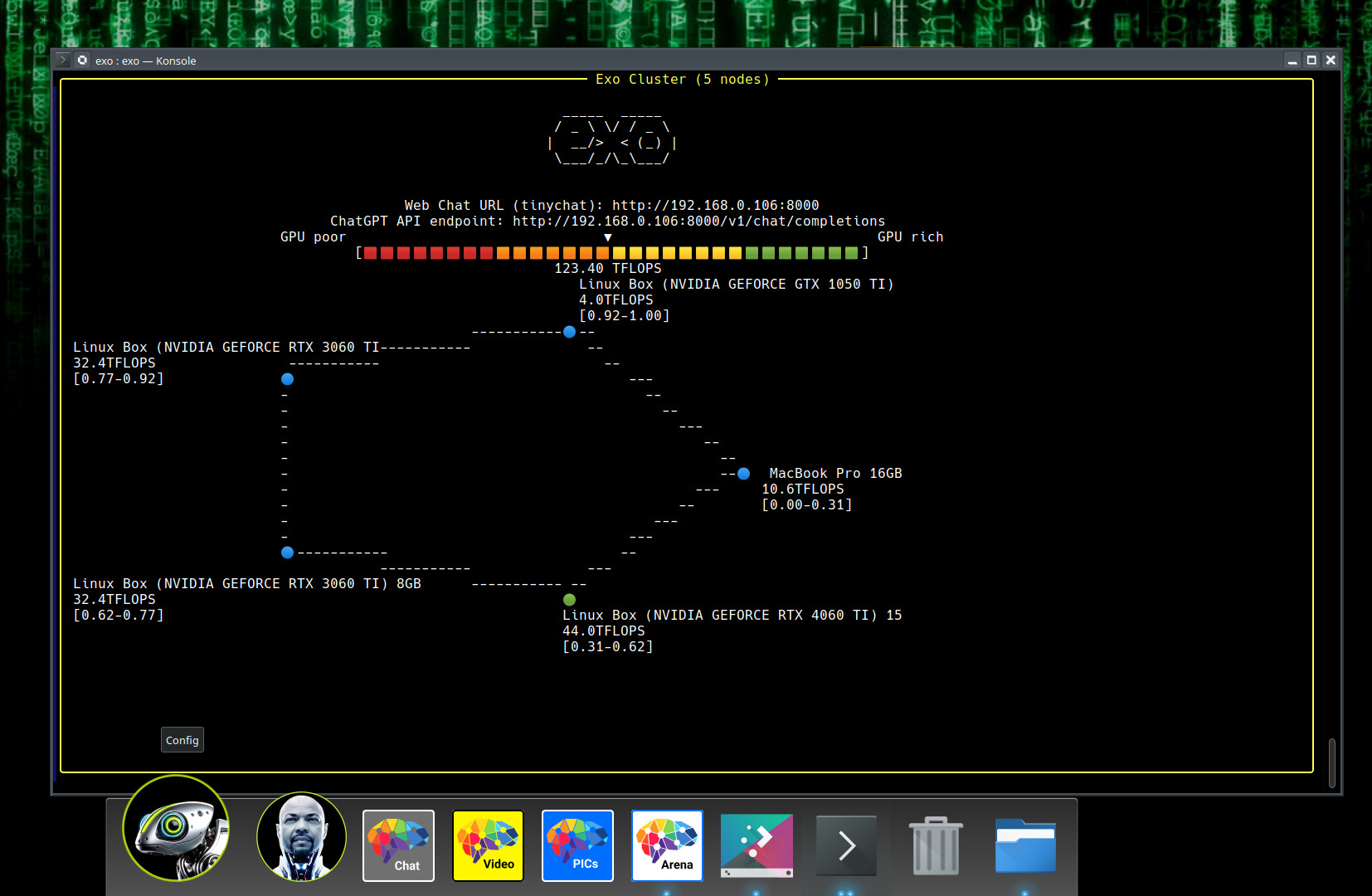
+ 0
- 3
docs/exo-screenshot.png
{kind=link}
|
||
|
||
|
||
|
||
+ 0
- 3
docs/ring-topology.png
{kind=link}
|
||
|
||
|
||
|
||